
Reinforcement Learning
Bandit Algorithm
Multi-Arm Bandit
For each time step $t$:
- $\epsilon$ Greedy Algorithm:
- if $rand() < \epsilon$ random select $k$ from $1$ to $K$
- if $rand() > \epsilon$, $k = \underset{a}{argmax\ }(Q(a))$
- Usually $\epsilon = \frac{1}{\sqrt {t}}$
- Take action $k$, record reward $r$
- Update action times
- Update action values:
- Interpretation:
Context-Free - UCB (Upper Confidence Bound)
- for a given option $a_i$: the expected return is $\bar x_{i,t} + \sqrt{\frac{2ln(n)}{n_{i,t}}}$
- first term - exploitation: the average return of item $i$ in the last $n_{i,t}$ trials
- second term - exploration: higher bounds for items which were selected not that often
Context-Free - Thompson Sampling
- beta distribution: $f(x;\alpha, \beta) = C \cdot x^{\alpha-1} \cdot (1-x)^{\beta-1} $. Note that $\alpha = \beta = 1$ gives the uniform distribution between 0 and 1.
- the beta distribution is the conjugate prior probability distribution for the Bernoulli distribution
- each time stamp, find the largest $\theta_i$, and update the parameter $\alpha_i$ and $\beta_i$ based on the reward $r$.
- The two parameters controls the mean and variance of the $\theta$ for each option.
Contextual Bandit
- The decision becomes making action $a$ based on the contextual vector $x_t$ and policy $\pi$
- get reward $r_{t,a}$ and revise policy $\pi$.
Markov Process
Markov Property of a state
- $P(S _{t+1} \vert S_t) = P(S _{t+1} \vert S_t, S _{t-1}, S _{t-2}, …)$, i.e, given the present, future is independent of past states.
Markov Process (MP)
- A sequence of random states $S$ with Markoe property, with the defintions of:
- $S$: a finite set of states
- $P$: transition function - $P(S _{t+1} = s’ \vert S_t=s)$
Markov Reward Process
Reward Function:
Return Function:
Value Function & Bellman Expectation Equation
- how good is it to be in a particular state
- Two components:
- Immediate reward
- Discounted value of the successor state
- Interpretation:
- The expected reward we get upon leaving that state
Analytical solution to Bellman Equation
- Computational complexity: $O(n^3)$
Markov Decision Process
New State Transition Probability - with action $a$
New Reward Function - with action $a$
Policy:
- Given a fixed policy, the MDP becomes MRP.
New State Transition Probability - with policy $\pi$
New Reward Function - with policy $\pi$
New Value Function & Bellman Expectation Equation - with policy $\pi$
New Action-Value Function - with policy $\pi$ and action $a$:
- how good is it to be in a particular state with a particular action
The relationship between $V$ and $q$
Rewrite New Action-Value Function
Rewrite New Value Function
Analytical solution to New Bellman Equation
Bellman Optimality Equation
- Optimal Policy
- Optimal Value Function
- Optimal Value-Action Function
Relationship between optimal functions
Rewrite Optimal Value Function
Model-based Approach (known $P$ and $r$)
Policy Evaluation
- Given MDP and policy $\pi$
- Using analytical solution to Bellman Equation Rewrite New Value Function
- Iteration from $k$ to $k+1$:
Policy Iteration
-
Policy Evaluation: Given $\pi_i$, evalute $V _{\pi_i}$ for each state $s$.
-
Policy Improvement: for each state $s$:
- Calculate $q(s,a)$ for each $a$
- Get updated policy $\pi _{i+1}(s)$
- Convergence: can be mathematically improved
- Stop Criteria:
- Assume current policy $\pi_i$ is already optimal
- Then $\pi_i$ is the optimal $\pi^*$, we have:
Example

Value Iteration
-
Directly find the optimal value function of each state instead of explicitly finding the policy
-
Value Update:
- Stop Criteria: Difference in $V$ value
- Optimal Policy: Action with max $V$ for each state
Example

Model-free Approach (Unknown $P$ and $r$)
Monte-Carlo (MC) Methods
- Update until the return is known
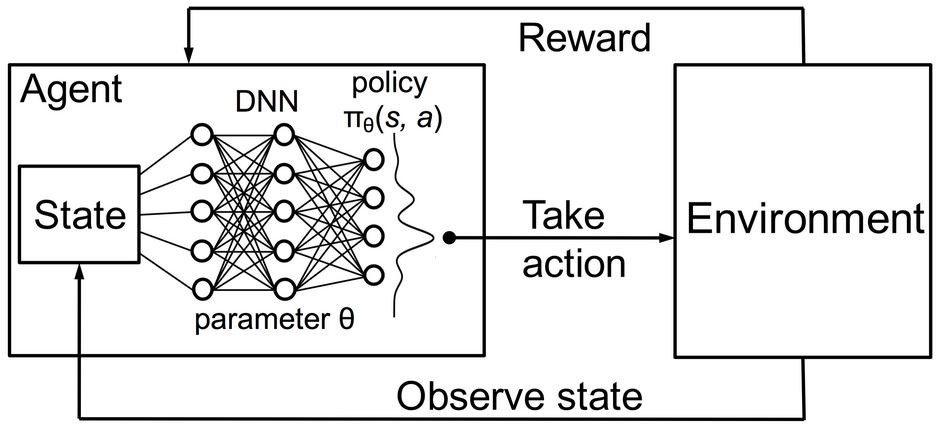
Policy Gradient - Monte Carlo REINFORCE
- The parameters $\theta$ in the $NN$ determines a policy $\pi _{\theta}$
- Define trajectory $\tau$
- Define total reward $r(\tau)$
- The loss function for a given policy $\pi _{\theta}$ is
- A mathematical property can be proved
- There are other revisions to replace $\color{blue}{ r(\tau)}$ with $\color{blue}{ \Phi(\tau, t)}$ to account for various problems. (e.g., standardization for all positive rewards, only calcultate the reward of $a_t$ from $t+1$, etc.). For example:
- Step 1: sample $\tau = (a_1, s_1, a_2, s_2, …, a_T, s_T)$ based on $\pi _{\theta}$, and get $r(\tau)$
- Step 2: Calculate back propagation for $\nabla_\theta J(\theta)$. For each time step $t$, it’s multiclass-classification $NN$ with target value as $\color{blue}{r(\tau)}$ or $\color{blue}{ \Phi(\tau, t)}$.
- Step 3: Update weiights $w$.
Drawbacks
- Update after each episode instead of each time step. There may be some bad actions.
- Require large sample size.
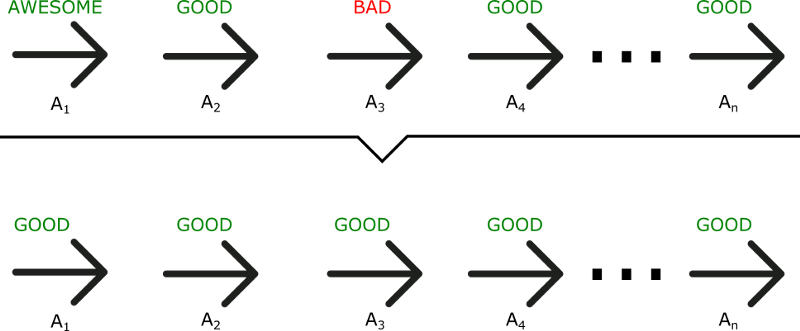
Example
see this notebook
Temporal-Difference (TD) Learning
- TD methods need to wait only until the next time step.
- At time t + 1 they immediately form a target and make a useful update.
Q-Learning
- Key idea: the learned action-value function $Q$ directly approximates $q^*$, the optimal action-value function
- Optimal Policy:
-
ref: http://www.incompleteideas.net/book/RLbook2020.pdf
- Initialize $Q$ table with $Q(s,a)$, note that $Q(terminal, \cdot)=0$
- Loop for each episode:
- Initialize S
- Loop for each step of episode:
- Choose action $a$ from S using policy derived from $Q$
- Take action $a$, observe reward $r$ and next state $s’$.
- Update $Q$ table:
- $s \leftarrow s’$
- until $s$ is terminal
Drawbacks:
- A finite set of actions. Cannot handle continuous or stochatisc action space.
Example

Deep Q-Learning
-
The parameters $w$ in the $NN$ determines a policy $Q(s,a \vert s, w)$ for each $a$.
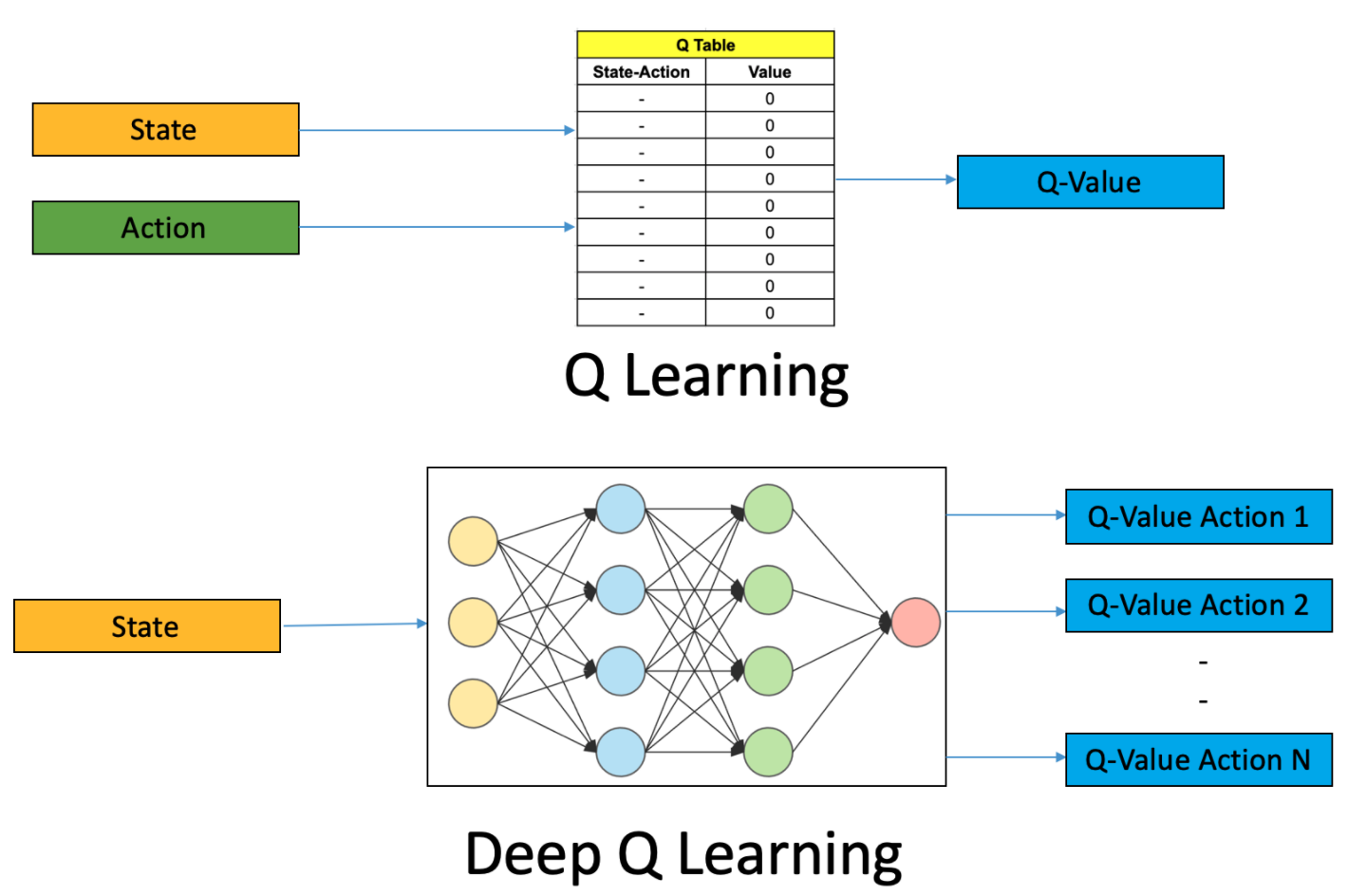
-
For episode in range(max_episode):
- For step in range(max_step):
- From $s$, run $NN$, and get $\hat Q_w(s,a)$ for each action a.
- Select and take best action $a^*$
- Get reward $r$ and Get next state $s’$.
- Run $NN$ again to get $Q(s’,a’)$ for each $a’$
- If $s’$ is not terminal: Set target value $\color{blue}{Q(s,a^*) = [r + \gamma \underset{a’}{max\ } Q(s’,a’)]} — [4]$
- Set loss $L= [\hat Q_w(s,a^) - \color{blue}{Q(s,a^)}] ^2$
- Update weights
- For step in range(max_step):
Example
see this notebook
Vanilla Actor-Critic
-
Instead of using $r(\tau)$ (which is the emprical, long-term reward based on T steps) and updating $\theta$ after one episode, here we use $Q(s,a)$ instead (There are also other variations). This enables updating weights every step.
- Policy Gradient:
- Actor:
- Deep Q-Learning
- Critic
Algorithm
- Intialize $s, \theta, w$, and sample $a$ from based on $\pi_\theta$.
- For $t = 1, 2, … ,T$
- get $s’$ and $r$
- get $a’$ based on $\pi_\theta(a’ \vert s’)$
- Update $\theta$ based on $[7]$
- Update $w$ based on $[8]$
- $a \leftarrow a’$, $s \leftarrow s’$.
Deep Deterministic Policy Gradient
- Both REINFORCE and the vanilla version of actor-critic method are on-policy: training samples are collected according to the target policy — the very same policy that we try to optimize for.
- DDPG is a model-free off-policy actor-critic algorithm
- https://arxiv.org/pdf/1509.02971.pdf

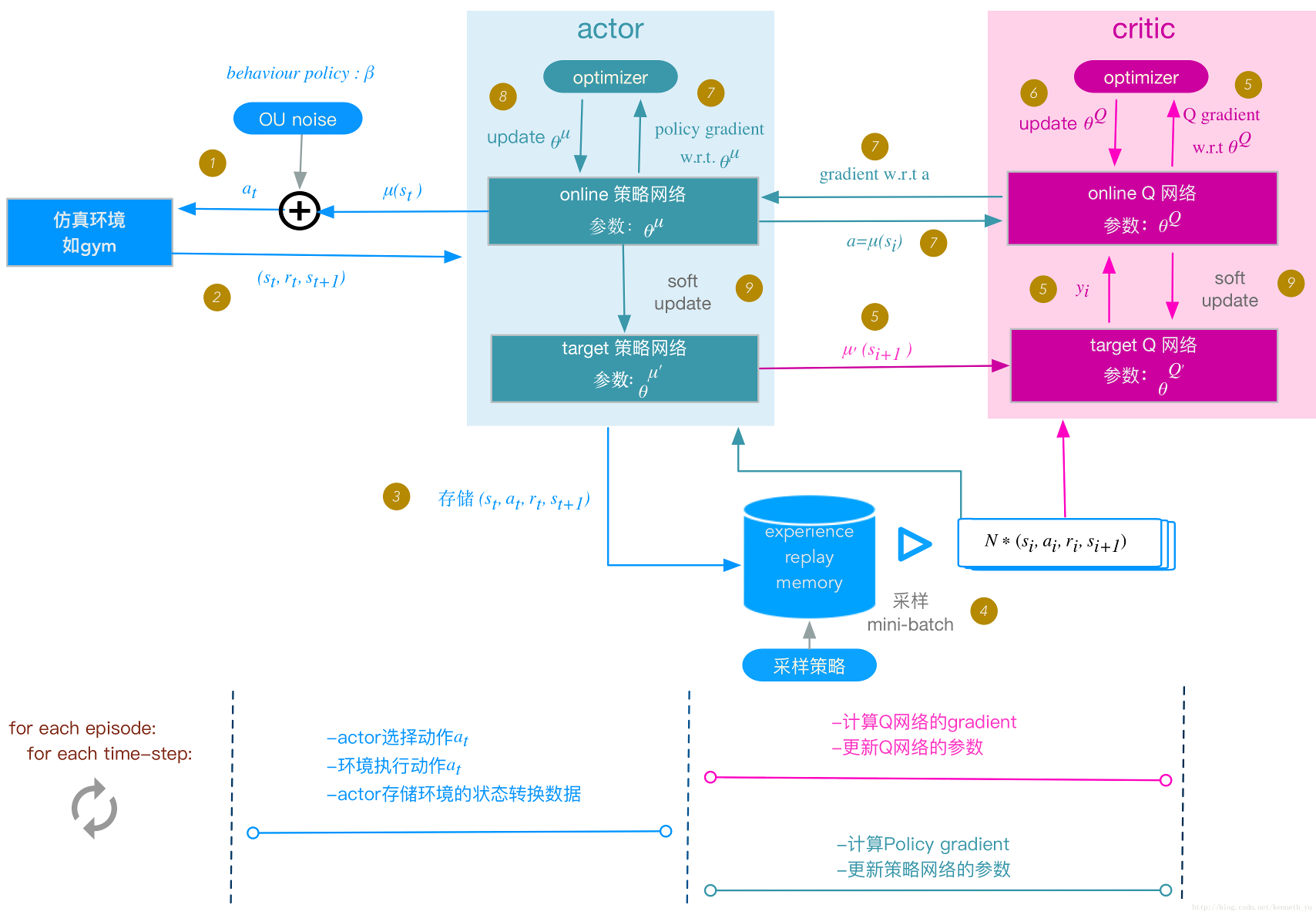
Comparison with Deep Q Learning
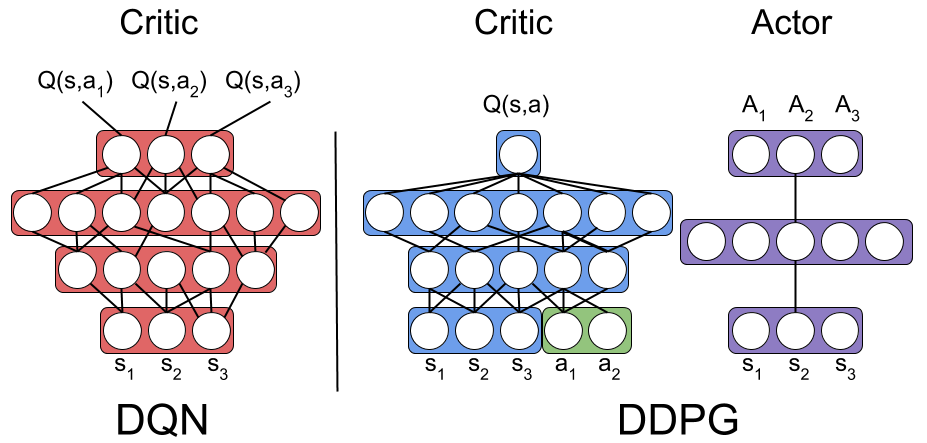
Comparison
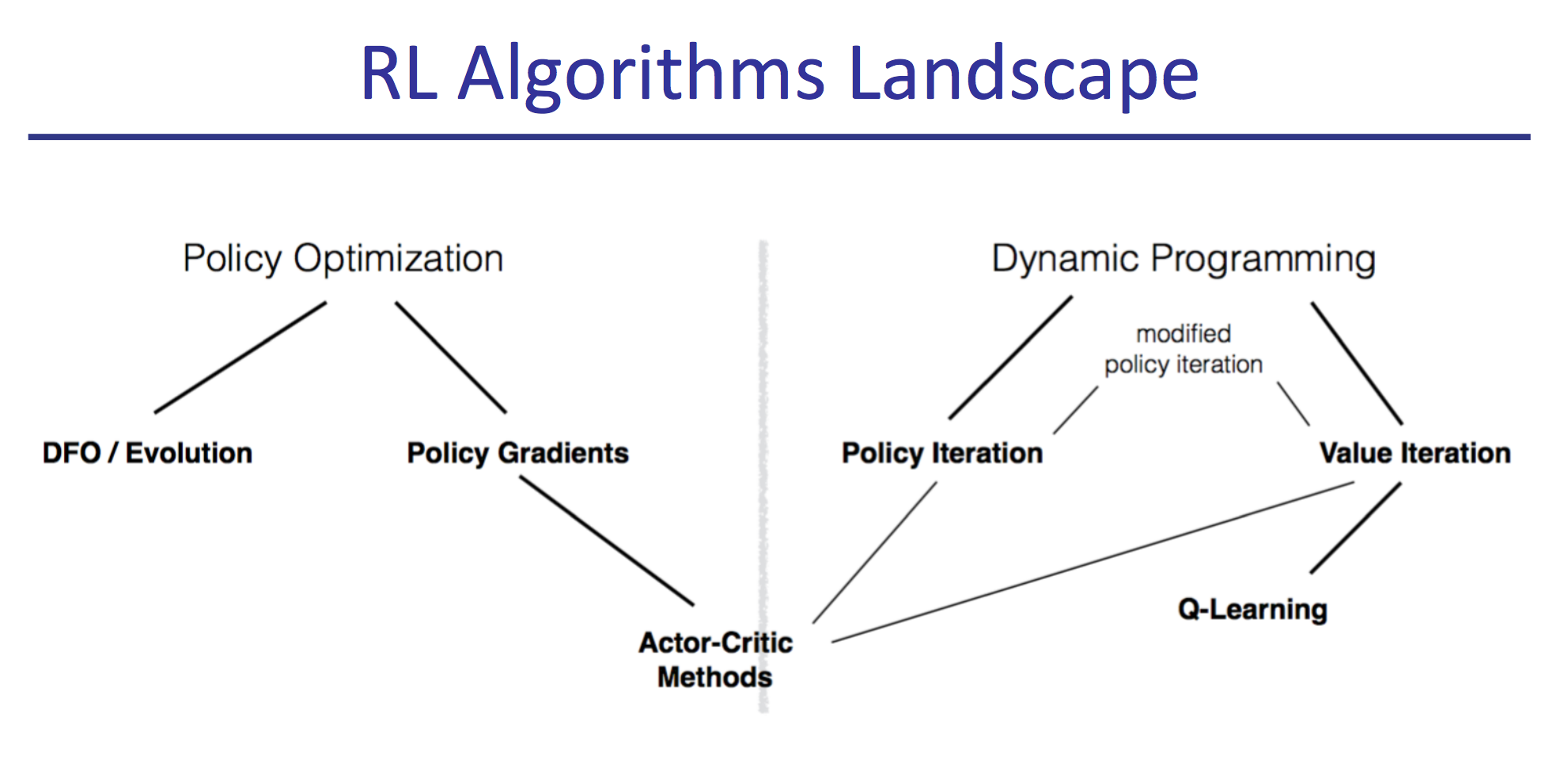
ref: https://antkillerfarm.github.io/rl/2018/11/18/RL.html
- Action space
- DQN cannot deal with infinite actions (e.g., driving)
- Policy gradient can learn stochastic policies while DQN has deterministic policy given state.
- Convergence
- Policy gradient has better convergence (policy is updated smoothly, while in DQN, slight change in Q value may completely change action/policy space, thus no convergence guarantee)
- Policy gradient has guaranteed for local minimum at least
- But usually policy gradient takes longer to train)
- Variance
- Policy gradient: Higher variance and sampling inefficiency. (Think of a lot of actions taken in a epoch before updating)
- Actor-Critic: TD update.
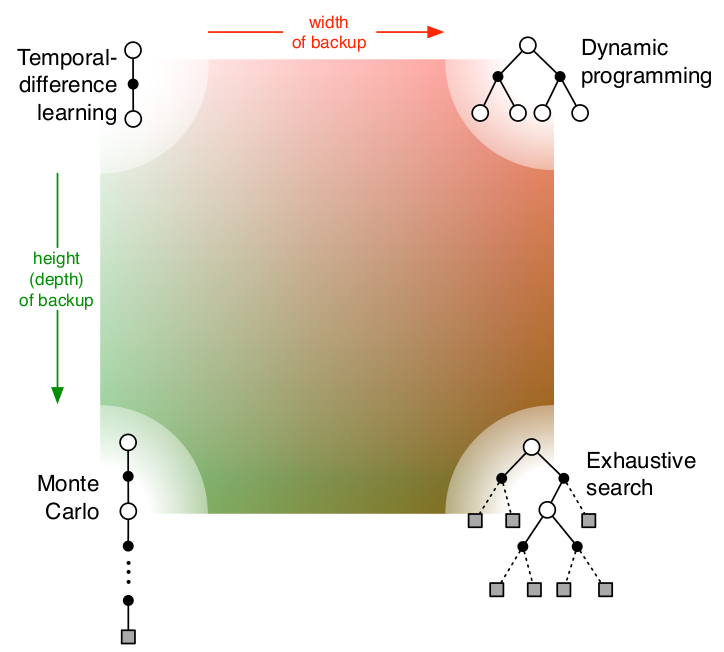
- Left: model unknown
- Right: model known
- Top: update each step
- Bottom: update each episode